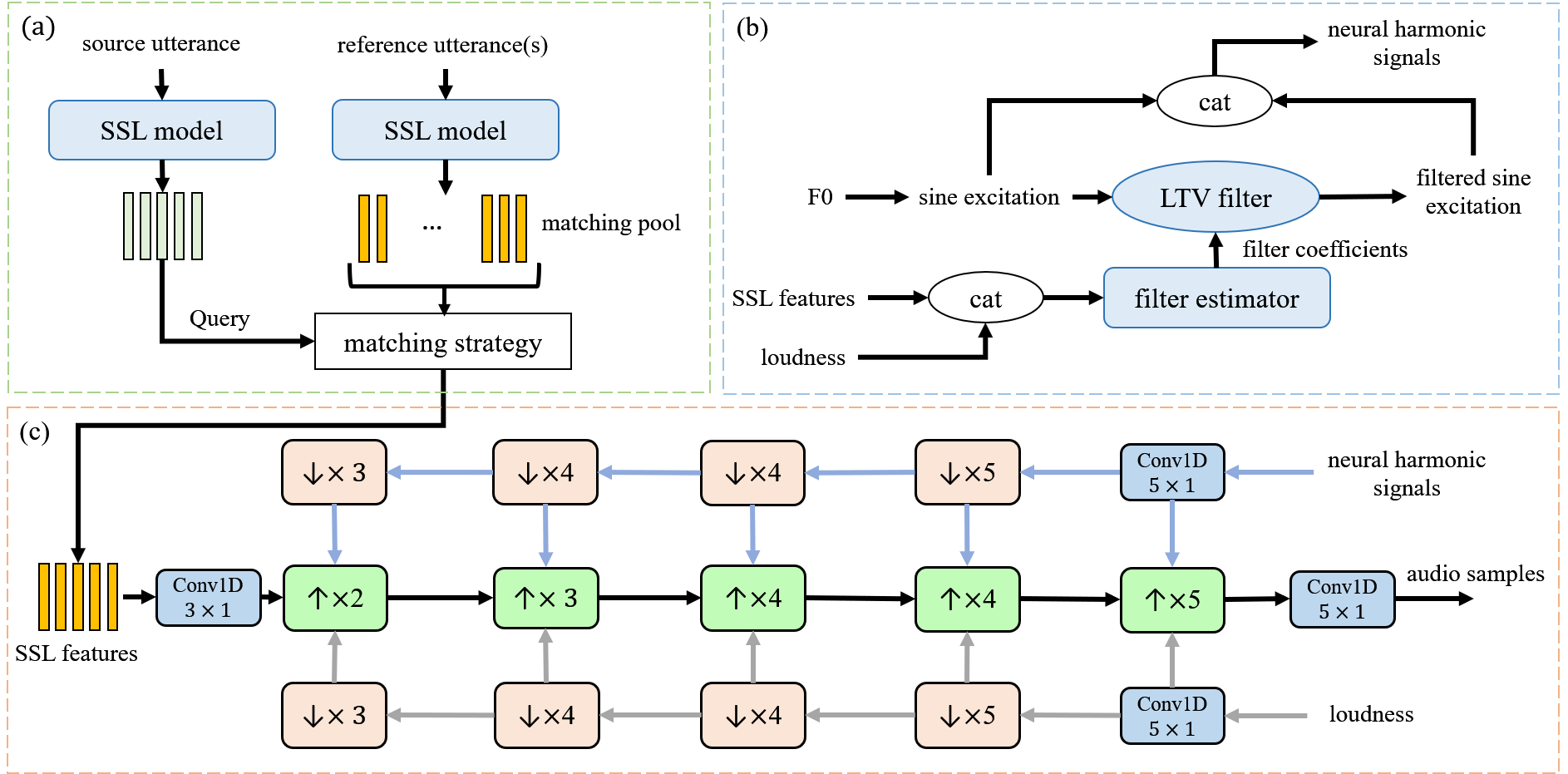
Any-to-any singing voice conversion (SVC) is confronted with a significant challenge of “timbre leakage” issue caused by insufficient disentanglement between the content and the speaker timbre. To address the formidable challenge of disentanglement, this study introduces a novel neural concatenative singing voice conversion (NeuCoSVC) framework. The NeuCoSVC framework comprises a self-supervised learning (SSL) representation extractor, a neural harmonic signal generator, and a waveform synthesizer.
The SSL model condenses the audio into a sequence of fixed-dimensional SSL features. The harmonic signal generator produces both raw and filtered harmonic signals leveraging a linear time-varying filter given condition features. Simultaneously, the audio generator creates waveforms directly from the SSL features, integrating both the harmonic signals and the loudness. During inference, the audio generator constructs converted waveforms directly by substituting source SSL representations with their nearest counterparts from a matching pool, which comprises SSL representations extracted from the target audio.
Consequently, this framework circumvents the challenge of disentanglement, effectively eliminating the issue of timbre leakage. Experimental results confirm that the proposed system delivers promising performance in the context of one-shot SVC across intra-language, cross-language, and cross-domain evaluations.
Compared Systems
SpkEmb-FastSVC: speaker embedding with FastSVC as the audio synthesizer. The speaker embeddings are extracted from ECAPA-TDNN1, and the linguistic features are extracted from WenetSpeech2.
NeuCoSVC (Proposed): the proposed system, consisting of neural concatenative method with the FastSVC architecture and the LTV harmonic filter module.
NeuCo-FastSVC: neural concatenative method with FastSVC as the audio synthesizer.
NeuCo-HiFi-GAN: neural concatenative method with nsf-HiFi-GAN3,4 as the audio synthesizer.
Audio Samples
We conduct any-to-any SVC experiments in three different scenarios: intra-language and cross-language conversions for in-domain tests, and intra-language conversions for cross-domain evaluation. In the in-domain SVC, target speakers’ singing voices are employed, whereas, in the cross-domain SVC, their speech voices serve as input. All speakers from the reference utterance remain unseen during training.
Note that the reference audio in intra-/cross-language scenarios is approximately 10 minutes long, while the one in the cross-domain scenario is about 30 seconds long, as mentioned in Section 4 of our paper. In the demo web, we’ve only included a single segment of around 10 seconds of the target person’s audio to demonstrate their voice characteristics. Additionally, singing audio of varying lengths are used in the duration study to assess the impact of reference audio duration on conversion quality.
Please feel free to explore the demo and refer to our paper for more detailed information on the experimental setup and results.
Intra-Language
Source
Reference
SpkEmb-FastSVC
NeuCoSVC (Proposed)
NeuCo-FastSVC
NeuCo-HiFi-GAN
Cross-Language
Source
Reference
SpkEmb-FastSVC
NeuCoSVC (Proposed)
NeuCo-FastSVC
NeuCo-HiFi-GAN
Cross-Domain
Source
Reference
SpkEmb-FastSVC
NeuCoSVC (Proposed)
NeuCo-FastSVC
NeuCo-HiFi-GAN
Duration Study
Source
Reference
5s
10s
30s
60s
90s
References
[1] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification,” in Proc. Interspeech, 2020, pp. 3830–3834.
[2] B. Zhang, H. Lv, P. Guo, Q. Shao, C. Yang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zeng et al., “Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,” in ICASSP. IEEE, 2022, pp. 6182–6186.
[3] X. Wang, S. Takaki, and J. Yamagishi, “Neural source-filter waveform models for statistical parametric speech synthesis,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 402–415, 2020.
[4] J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 17 022–17 033.